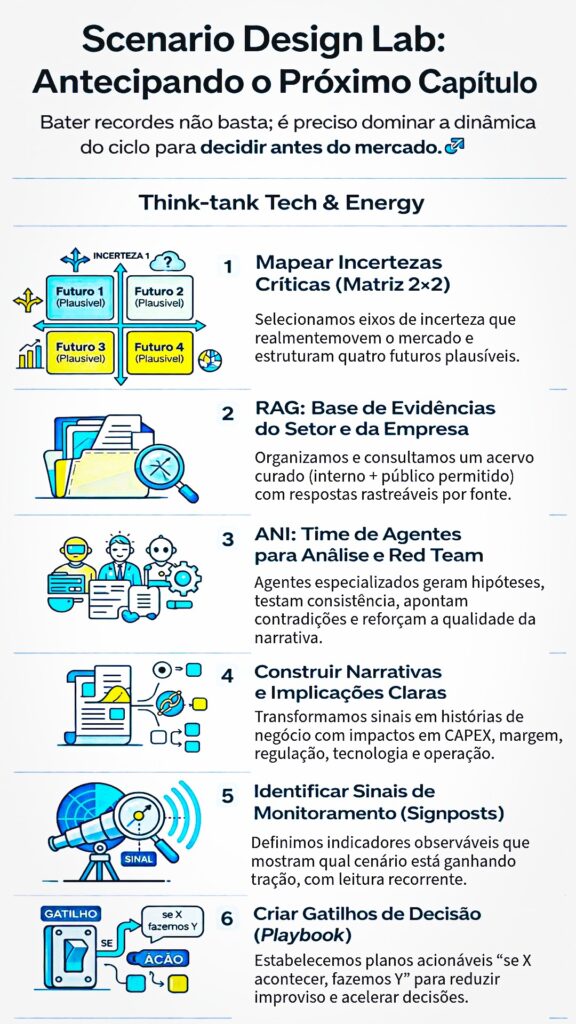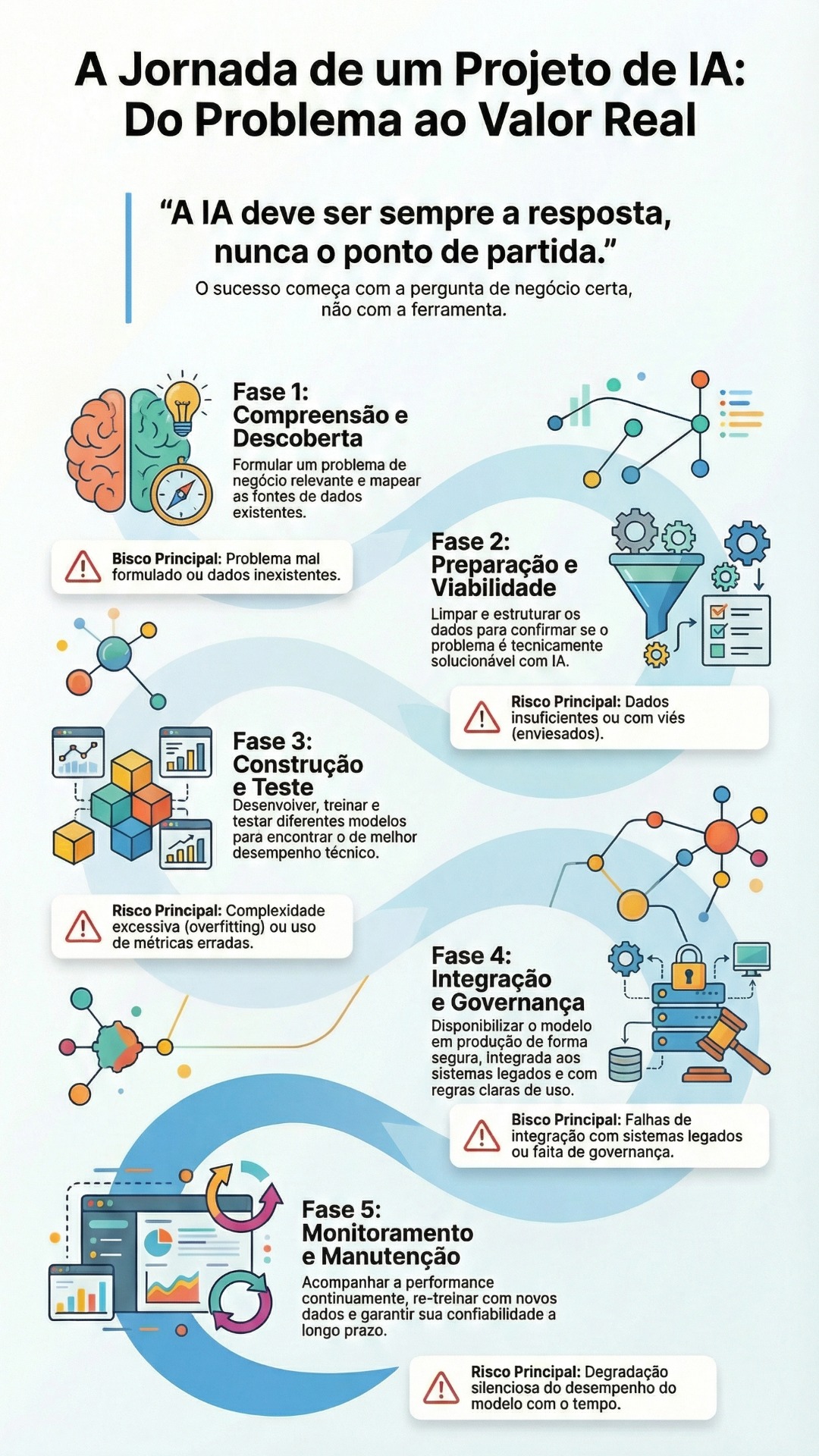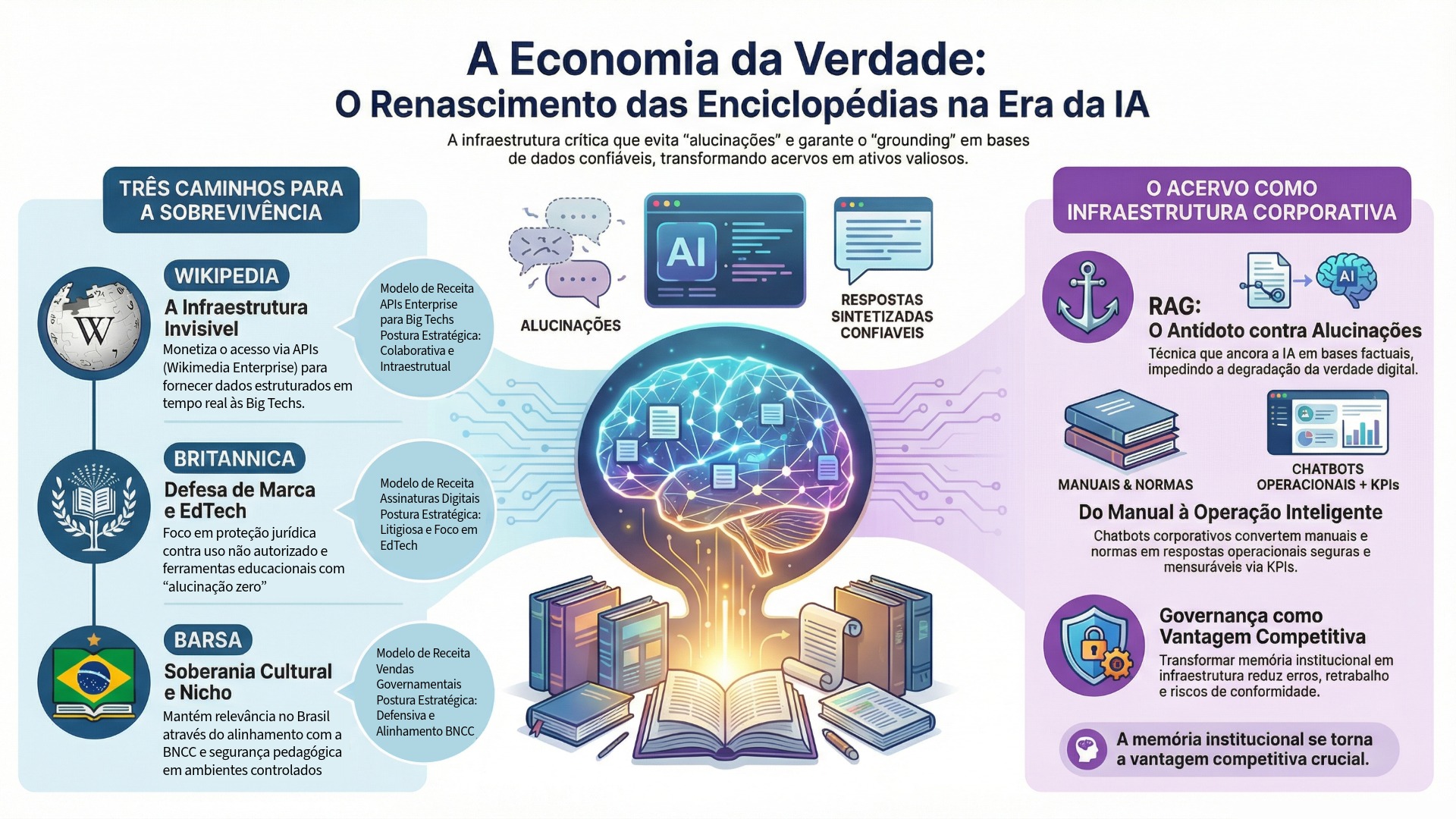
Sumário Executivo
A revolução da Inteligência Artificial Generativa (IA Gen), impulsionada por Grandes Modelos de Linguagem (LLMs), precipitou uma transformação estrutural na economia do conhecimento. O que antes era uma disputa por atenção — mediada por motores de busca, portais e publicidade — converteu-se em uma disputa por integridade factual, rastreabilidade e pela própria infraestrutura epistêmica que alimenta sistemas de geração. A mudança de paradigma é central: a lógica “busca → links → verificação humana” foi substituída por “pergunta → síntese única → risco de alucinação”. Neste cenário, o conhecimento deixou de ser apenas conteúdo e passou a ser um insumo crítico de engenharia: sem lastro, as respostas se degradam; com lastro, a IA se torna operacionalmente útil, defensável e escalável.
O relatório demonstra que o “conhecimento verificado” se tornou a commodity mais valiosa da era da IA — não por sua raridade absoluta, mas por sua capacidade de conter riscos sistêmicos (alucinações, circularidade informacional, citogênese e “model collapse”). A técnica de Geração Aumentada por Recuperação (RAG) consolida esse deslocamento: o valor migra do “modelo” para a “base confiável”, e a vantagem competitiva passa a residir no acesso estruturado, atualizado e juridicamente seguro a corpora curados por humanos. Em termos econômicos, a verdade deixa de ser apenas um ideal editorial e passa a ser uma forma de infraestrutura com custo, governança e precificação.
A análise compara três respostas estratégicas ao novo regime:
- Wikimedia/Wikipedia (colaboração infraestrutural e monetização por serviço) — A criação da Wikimedia Enterprise e os acordos com Big Tech sinalizam uma estratégia de sobrevivência pragmática: transformar um bem comum (conteúdo aberto) em receita recorrente via APIs de alto desempenho, oferecendo atualização em tempo real, dados estruturados e garantias operacionais que scraping e dumps públicos não entregam com eficiência. Essa escolha responde ao paradoxo “zero-click”: o tráfego humano tende a cair à medida que resumos por IA intermediada dominam a navegação, afetando doações e visibilidade. A monetização via Enterprise funciona como hedge: se a Wikipedia se tornar “infraestrutura invisível”, ainda assim será remunerada por sustentar o ecossistema.
- Encyclopædia Britannica (defesa de PI + reputação como ativo de luxo) — A Britannica adota uma postura litigiosa e de proteção agressiva da propriedade intelectual, interpretando buscadores por IA como substitutos de mercado que desintermediam audiência e receita. O litígio contra a Perplexity AI é apresentado como um marco: além de copyright, a disputa envolve o risco reputacional de alucinações atribuídas à marca, deslocando o debate do técnico para o jurídico (responsabilidade, origem e diluição de marca). Em paralelo, a Britannica pivotou para EdTech, oferecendo IA “controlada” e restrita ao próprio acervo — uma tentativa de vender confiança como produto premium em ambientes onde erro é inaceitável.
- Barsa (resiliência local via soberania cultural e mercado institucional) — No Brasil, a Barsa se mantém relevante por uma estratégia de nicho com alta defensibilidade: foco B2B/B2G, alinhamento pedagógico, controle de ambiente e valor de curadoria contextualizada. Em um cenário de conectividade desigual e preocupação educacional com desinformação, o “jardim murado” torna-se diferencial: previsibilidade, adequação curricular e segurança informacional. A ausência de acordos públicos de licenciamento de IA sugere uma postura defensiva/protecionista (ou oportunidade ainda não explorada), preservando exclusividade do acesso humano direto ao acervo.
O tópico sobre chatbots corporativos baseados em acervos internos — amplia o argumento: a “economia da verdade” não é apenas um fenômeno da esfera pública (Wikipedia, Britannica, Barsa), mas um movimento que penetra o núcleo das organizações. À medida que LLMs começam a mediar decisões, diagnósticos, propostas e rotinas, as empresas enfrentam sua própria crise epistêmica: acervos dispersos, normas em versões conflitantes, dependência de especialistas-gargalo, retrabalho e risco de não conformidade. O relatório sustenta que o equivalente corporativo de uma enciclopédia é o conjunto de documentos que historicamente estruturou a governança empresarial — manuais de produto, manuais de engenharia, normas internas, compliance, lições aprendidas, missão, propósito, planejamento estratégico, relatórios de sustentabilidade — e que esse acervo deve ser transformado em infraestrutura operacional de acesso governado.
Nesse novo cenário, um Chatbot de IA corporativo com acesso restrito, ancorado no acervo e orientado por OKRs/KPIs, emerge como mecanismo de alinhamento em escala: reduz fricção de busca, padroniza interpretações, acelera onboarding, melhora produtividade e reforça compliance by design. O valor não reside em “gerar texto”, mas em oferecer respostas com lastro, versão, contexto e trilha de auditoria — convertendo documentação em capacidade executável. A telemetria do uso do chatbot, por sua vez, transforma dúvidas recorrentes em backlog de melhoria contínua, refinando processos e elevando maturidade organizacional.
Como ilustração aplicada, o relatório posiciona o projeto desenvolvido pela nMentors Academy no CPFL nas Universidades como um caso de implementação dessa tese em ambiente institucional: o chatbot é apresentado não como um FAQ sofisticado, mas como um ativo de governança e produtividade, capaz de orientar navegação em acervo, reduzir dependência de suporte humano e sustentar consistência informacional com rastreabilidade. A narrativa de merchandising reforça a proposta: organizações que tratam seu acervo como infraestrutura epistêmica ganham vantagem estrutural — decidem melhor, executam mais rápido e erram menos.
Por fim, a conclusão do relatório aponta para uma convergência: o futuro da informação — pública ou corporativa — não depende da capacidade das máquinas de produzir linguagem, mas da capacidade das instituições de verificar, versionar, contextualizar e responsabilizar a verdade. Enciclopédias evoluem de repositórios para âncoras de realidade; empresas são compelidas a fazer o mesmo com sua memória institucional. O dilema societário permanece: se a verdade for empacotada apenas como serviço premium, cresce o risco de desigualdade cognitiva. O desafio executivo, por outro lado, é inequívoco: na era dos LLMs, governança do conhecimento deixa de ser custo administrativo e passa a ser vantagem competitiva mensurável.
1. Introdução: A Crise Epistêmica e a Valorização da Curadoria Humana
A ascensão de ferramentas como ChatGPT (OpenAI), Claude (Anthropic), Gemini (Google) e Perplexity redefiniu o acesso à informação. O paradigma da “busca”, onde o usuário recebe uma lista de links para investigar, foi substituído pelo paradigma da “geração”, onde a máquina sintetiza uma resposta única. Esta mudança introduziu o risco sistêmico da “alucinação” — a fabricação confiante de falsidades por sistemas probabilísticos. Neste ecossistema, as bases de dados enciclopédicas deixaram de ser apenas fontes de consulta para humanos e tornaram-se o lastro fundamental, ou “grounding”, necessário para impedir a degradação da verdade digital.
1.1 A Necessidade do Lastro Humano
Os modelos de IA operam prevendo a próxima palavra em uma sequência, sem uma compreensão intrínseca de verdade ou mentira. Para mitigar erros, utiliza-se a técnica de Geração Aumentada por Recuperação (RAG – Retrieval-Augmented Generation), que exige acesso a bases de dados factuais, atualizadas e estruturadas. É neste ponto que a Wikipedia, a Britannica e a Barsa deixam de ser concorrentes diretas pela atenção do leitor e tornam-se infraestruturas críticas. Sem o conteúdo curado por humanos dessas fontes, as IAs correm o risco de “Colapso do Modelo” (Model Collapse), um fenômeno degenerativo causado pelo treinamento recursivo em dados sintéticos gerados por outras IAs.
1.2 O Dilema Econômico
As enciclopédias tradicionais, que perderam a hegemonia de mercado nas décadas de 1990 e 2000 para a gratuidade da web, enfrentam agora um paradoxo. A IA é uma ameaça existencial que desvia tráfego e receitas publicitárias (o fenômeno “Zero-Click”), mas é também a maior oportunidade de monetização de seus acervos em décadas. A decisão de licenciar, bloquear ou processar define a sobrevivência dessas instituições.
2. O Pivô da Wikimedia: De Doações a Infraestrutura da IA
A Wikipedia, historicamente financiada por um modelo filantrópico de pequenas doações, enfrenta um desafio de sustentabilidade sem precedentes. O tráfego de bots de IA, buscando dados para treinamento, aumentou drasticamente a carga nos servidores, enquanto o tráfego humano — e a visibilidade para campanhas de doação — começou a declinar.
2.1 A Criação da Wikimedia Enterprise
Em resposta, a Wikimedia Foundation lançou a Wikimedia Enterprise, uma subsidiária comercial (LLC) projetada para vender serviços de dados para empresas que utilizam o conteúdo da enciclopédia em escala industrial. Em comemoração ao seu 25º aniversário, a fundação anunciou parcerias formais com um consórcio de líderes em IA: Microsoft, Meta, Amazon, Perplexity e Mistral AI.
2.1.1 Mecânica Técnica e Valor Agregado
As Big Techs sempre puderam acessar a Wikipedia gratuitamente através dos “dumps” de dados públicos ou scraping. No entanto, esses métodos são ineficientes, custosos para processar e frequentemente desatualizados. A Wikimedia Enterprise oferece valor através de APIs de alto desempenho:
- Realtime API: Fornece um fluxo de atualizações em tempo real. Quando um editor corrige um fato na Wikipedia, essa correção é enviada instantaneamente para a IA da Microsoft ou da Meta, reduzindo o tempo de propagação de erros.
- Snapshot API: Oferece downloads completos e estruturados, limpos de vandalismo e formatados para ingestão em LLMs, economizando milhões de dólares em engenharia de dados para as empresas clientes.
- Garantia de Origem: As empresas pagam pela certeza de estarem usando a versão mais precisa e estável dos artigos, mitigando riscos legais e de reputação.
2.1.2 A Filosofia do “Fair Share” (Parte Justa)
Jimmy Wales, fundador da Wikipedia, articulou a justificativa moral para a cobrança: as empresas que lucram bilhões com a IA não devem ter seus custos de infraestrutura subsidiados por doadores individuais de uma organização sem fins lucrativos.
- Sustentabilidade: A receita gerada (estimada em dezenas de milhões, embora números exatos não sejam públicos) é reinvestida na fundação para manter o site gratuito e sem anúncios para o público geral.
- Independência: Ao diversificar a receita, a Wikimedia reduz sua dependência de campanhas de arrecadação agressivas que podem alienar leitores.
2.2 Impacto na Comunidade e Governança
A decisão de monetizar o conteúdo gerado por voluntários gerou debates complexos sobre a ética do trabalho colaborativo.
- A Tensão do Voluntariado: A Wikipedia é construída por cerca de 250.000 editores voluntários. A venda do fruto desse trabalho para corporações com fins lucrativos exige uma navegação diplomática cuidadosa. A fundação argumenta que a receita garante a sobrevivência da plataforma, mas existe o risco de desmotivação se os voluntários sentirem que estão trabalhando “de graça” para enriquecer a Amazon ou a Meta.
- Licenciamento Copyleft: O conteúdo da Wikipedia está sob licença Creative Commons (CC BY-SA), que permite uso comercial desde que haja atribuição e compartilhamento pela mesma licença. As parcerias da Enterprise contornam a necessidade de as empresas abrirem seus modelos proprietários, focando na prestação de serviço (a API) em vez da venda do copyright em si.
2.3 O Paradoxo do Tráfego e a Relevância
A Wikipedia relatou uma queda de 8% no tráfego humano em 2024, correlacionada diretamente com a ascensão dos resumos de IA nos motores de busca.
- Invisibilidade da Infraestrutura: A Wikipedia corre o risco de se tornar uma “camada invisível” da web — essencial, onipresente, mas raramente visitada diretamente. O sucesso da Wikimedia Enterprise é, portanto, uma estratégia de hedge (proteção): se os usuários pararem de visitar o site, a fundação ainda será remunerada através das empresas que intermediam o acesso ao conhecimento.
3. A Contraofensiva da Encyclopædia Britannica: Litígio e Precisão
Enquanto a Wikipedia busca a colaboração pragmática, a Encyclopædia Britannica adotou uma postura de confronto direto e proteção agressiva de sua propriedade intelectual. Com mais de 250 anos de história, a Britannica não possui a escala de voluntários da Wikipedia, mas detém um ativo inestimável: a autoridade editorial centralizada e a responsabilidade jurídica sobre seu conteúdo.
3.1 O Processo Britannica v. Perplexity AI
O litígio iniciado pela Britannica e sua subsidiária Merriam-Webster contra a Perplexity AI é um marco na jurisprudência da IA. Diferente de processos movidos por autores individuais ou artistas, este é um confronto corporativo sobre a viabilidade econômica do jornalismo e da edição profissional.
3.1.1 As Acusações de Propriedade Intelectual
A Britannica alega que a Perplexity realizou “scraping” ilegal de seus sites, ignorando protocolos de exclusão (robots.txt) e medidas de proteção digital.
- Substituição de Mercado: A acusação central é que a Perplexity não atua como um motor de busca (que leva o usuário à fonte), mas como um substituto de mercado. Ao fornecer a resposta completa extraída da Britannica, a Perplexity “rouba” a visita, a impressão de anúncio e a oportunidade de conversão de assinatura, destruindo o modelo de negócios da editora.
- Violação de Direitos Autorais: A reprodução de trechos inteiros ou resumos substanciais sem licença é atacada como uma violação direta do Copyright Act, desafiando a defesa de “uso justo” (Fair Use) frequentemente utilizada pelas empresas de IA.
3.1.2 A Questão da Marca e as Alucinações (Lanham Act)
Um aspecto inovador e crítico do processo é a alegação de violação da Lei Lanham (marca registrada). A Britannica acusa a Perplexity de gerar alucinações — informações falsas — e atribuí-las à Britannica ou Merriam-Webster.
- Diluição de Reputação: Para uma marca cujo valor é sinônimo de precisão (como a Britannica), ter falsidades atribuídas a ela por uma IA é catastrófico. O processo argumenta que isso dilui a marca e confunde o consumidor, criando uma falsa associação de origem. Isso transforma a alucinação da IA de um problema técnico em um problema legal de difamação corporativa.
3.2 O Pivô para EdTech: Britannica Studio e IA Controlada
A Britannica não rejeita a IA; ela rejeita a IA não licenciada. A empresa está pivotando agressivamente para se tornar uma plataforma de tecnologia educacional (EdTech), oferecendo suas próprias ferramentas de IA “seguras”.
3.2.1 Britannica AI Chatbot e Studio
A empresa lançou ferramentas como o Britannica AI Chatbot e o Britannica Studio, projetados especificamente para o ambiente escolar.
- Grounding Restrito: Ao contrário do ChatGPT, que treina na web aberta, as ferramentas da Britannica restringem suas respostas estritamente ao conteúdo verificado de seu próprio acervo. Isso permite prometer “alucinação zero” ou, no mínimo, rastreabilidade total.
- Ferramentas para Professores: O Britannica Studio permite que educadores gerem planos de aula, questionários e textos adaptados por nível de leitura, usando a IA para processar o conteúdo confiável da Britannica. A proposta de valor é a economia de tempo com segurança pedagógica, algo que o ChatGPT aberto não pode garantir.
4. O Caso Brasileiro: A Resiliência da Barsa e o Mercado B2G
No Brasil, a marca Barsa ocupa um lugar singular no imaginário coletivo. Sob o controle da multinacional espanhola Editora Planeta desde 2000, a Barsa adaptou-se à era digital de uma maneira distinta, focando menos no consumidor final (B2C) e mais nas vendas institucionais para governos e escolas (B2G/B2B).
4.1 Barsa na Rede: Soberania Digital e Pedagógica
A plataforma Barsa na Rede é a evolução digital da enciclopédia física. Com 187.000 verbetes, ela não compete por tráfego de busca global com a Wikipedia, mas posiciona-se como uma ferramenta de infraestrutura educacional.
4.1.1 Alinhamento com a BNCC
A grande vantagem competitiva da Barsa no mercado brasileiro é o alinhamento nativo com a Base Nacional Comum Curricular (BNCC).
- Curadoria Contextualizada: Enquanto IAs globais e a Wikipedia oferecem conhecimento geral, a Barsa estrutura seu conteúdo (artigos, mapas, estatísticas) especificamente para atender às competências exigidas pelo Ministério da Educação do Brasil. Isso torna a plataforma um ativo indispensável para gestores escolares que precisam cumprir metas curriculares oficiais.
- Tropicalização do Conhecimento: A Barsa preserva a visão de mundo brasileira, com ênfase em história, geografia e literatura locais. IAs treinadas majoritariamente em corpus de língua inglesa (e depois traduzidas) frequentemente falham em captar nuances culturais regionais ou alucinam sobre fatos locais específicos. A Barsa atua como guardiã dessa soberania narrativa.
4.2 O Mercado de Governo (B2G) e a Inclusão Digital
O Brasil possui vastas áreas com conectividade precária. Neste cenário, a Barsa mantém relevância através de modelos híbridos.
- Acervos Físicos e Offline: A venda de coleções impressas e soluções offline para bibliotecas escolares em municípios remotos continua sendo uma fonte de receita e impacto social. Relatórios de gestão pública indicam a aquisição de volumes da Barsa para compor o acervo de escolas e projetos de segurança escolar, onde o acesso à internet é limitado ou restrito para evitar distrações.
- Segurança contra Desinformação: Em um ambiente escolar preocupado com fake news e o uso indevido de celulares e IAs para “cola”, a Barsa oferece um ambiente controlado (“Walled Garden”). A Editora Planeta vende a segurança de que o aluno não será exposto a conteúdo impróprio ou não verificado, um argumento de venda poderoso para pais e diretores.
4.3 A Ausência de Acordos de IA
Diferentemente da Wikimedia, não há evidências públicas de que a Barsa/Editora Planeta tenha firmado acordos de licenciamento em massa com Big Techs para treinamento de IA.
- Protecionismo ou Oportunidade? Isso pode ser interpretado como uma estratégia de manter a exclusividade do conteúdo para seus assinantes pagantes ou como uma oportunidade ainda não explorada. O corpus da Barsa seria valiosíssimo para treinar LLMs em Português Brasileiro de alta qualidade, reduzindo o viés anglófono das IAs atuais. A ausência desses acordos sugere que a Planeta aposta na valorização do acesso humano direto via assinatura institucional, em vez de diluir seu conteúdo no “lago de dados” das IAs.
5. Análise Comparativa dos Modelos de Negócios e Estratégias
A tabela abaixo sintetiza as divergências estratégicas entre as três organizações frente ao desafio da Inteligência Artificial.
| Dimensão Estratégica | Wikipedia (Wikimedia Foundation) | Encyclopædia Britannica | Enciclopédia Barsa (Editora Planeta) |
| Modelo de Receita Principal | Doações Filantrópicas + Receita B2B via API Enterprise | Assinaturas Digitais (Escolas/Consumidores) + Licenciamento | Vendas Institucionais (Governo/Escolas) + Venda Direta (Papel/Digital) |
| Postura frente à IA | Colaborativa/Infraestrutural: Fornecedor oficial de dados para Big Tech. | Litigiosa/Concorrente: Processa por uso indevido e lança produtos próprios de IA. | Defensiva/Nicho: Foco na curadoria humana como antídoto à IA e suporte à BNCC. |
| Acesso aos Dados (Tech) | APIs de Alta Performance (Realtime/Snapshot) para clientes pagos. | Dados proprietários fechados. Acesso via login ou integração LTS. | Plataforma fechada (Barsa na Rede). Sem API pública conhecida para IA. |
| Proposta de Valor na Era IA | “A fonte da verdade para a internet” (Grounding global). | “Confiança e segurança pedagógica” (EdTech premium). | “Soberania cultural e alinhamento curricular” (Mercado Brasileiro). |
| Tratamento Jurídico | Copyleft (CC BY-SA) com monetização de serviço/SLA. | Copyright tradicional rígido. Alegação de violação de marca por alucinação. | Copyright tradicional. Foco em contratos de venda de ativos (livros/licenças). |
| Risco Principal | Queda nas doações devido à invisibilidade (Zero-Click). | Perda de relevância se IAs se tornarem “boas o suficiente” sem licença. | Obsolescência tecnológica se não integrar IA na plataforma. |
6. Aprofundamento Técnico: RAG, Grounding e a Economia da Verdade
A dinâmica entre essas enciclopédias e as IAs não é apenas comercial, é profundamente técnica. A arquitetura dos sistemas de IA modernos criou uma dependência funcional desses acervos.
6.1 Retrieval-Augmented Generation (RAG)
O RAG é o mecanismo que permite a uma IA responder perguntas factuais com precisão.
- O Usuário pergunta: “Quem descobriu o Brasil?”
- A IA recupera: O sistema busca em um índice confiável (Wikipedia ou Barsa).
- A IA gera: O modelo lê o texto recuperado e formula a resposta baseada apenas naquele texto.
- O Valor da Wikipedia Enterprise: Para que o RAG funcione em escala global, a IA precisa de acesso instantâneo e estruturado. A API da Wikipedia permite que o índice da IA esteja sempre sincronizado com a última edição humana. Sem isso, a IA responderia com dados de seu último treinamento (que pode ter ocorrido há meses), perdendo eventos recentes.
6.2 O Problema da Circularidade (Citogênese)
A Wikipedia enfrenta o risco de editores usarem IAs para escrever artigos, que são então usados para treinar IAs, criando um ciclo de feedback de baixa qualidade.
- Contramedidas: A comunidade da Wikipedia implementou políticas estritas e bots de detecção para remover conteúdo gerado por IA. Esse “trabalho de limpeza” é, ironicamente, um dos maiores valores que a Wikimedia vende para as Big Techs. As empresas de IA pagam a Wikimedia para garantir que não estão treinando seus modelos em conteúdo gerado por seus próprios concorrentes ou versões anteriores de si mesmas.
6.3 Verificação de Fatos como Serviço (FaaS)
Estamos caminhando para um modelo de “Fact-checking as a Service”.
- A Britannica e a Barsa estão posicionadas para oferecer serviços onde a “verdade” é garantida juridicamente. Em contextos corporativos (Direito, Medicina, Engenharia), uma alucinação é inaceitável. Empresas preferirão pagar pela API da Britannica (que garante a fonte) do que usar um ChatGPT gratuito que pode inventar leis ou sintomas. A precisão torna-se um produto de luxo.
7. Impacto Societal e Educacional
A penetração da IA nas escolas, mediada ou combatida pelas enciclopédias, está redefinindo o processo de aprendizagem.
7.1 A Mudança da Pesquisa para a Pronta-Resposta
Educadores relatam que alunos estão deixando de “pesquisar” (ler vários artigos, sintetizar) para “promptar” (pedir a resposta pronta).
- O Papel da Barsa e Britannica: Escolas estão utilizando plataformas como o Britannica Studio e a Barsa na Rede para forçar o aluno a interagir com fontes primárias e secundárias verificadas. O ambiente fechado dessas plataformas impede o “copia e cola” cego de chatbots alucinatórios.
- Letramento em IA: A Britannica integrou o letramento em IA em seus produtos, mostrando aos alunos como a IA gerou a resposta e destacando as fontes originais, promovendo uma visão crítica sobre a tecnologia.
7.2 O Risco da Desigualdade Cognitiva
A monetização do acesso a dados de alta qualidade pode criar um abismo.
- A Elite: Terá acesso a IAs “grounded” em Britannica e bases pagas, livres de alucinações e viés.
- A Massa: Utilizará modelos gratuitos, treinados em dados abertos da web (scraping), sujeitos a desinformação e publicidade oculta.
- A Wikipedia, ao manter seu acesso gratuito subsidiado pelas Big Tech, atua como o principal baluarte contra essa distopia, garantindo que um “mínimo existencial de verdade” permaneça acessível a todos, independentemente da capacidade de pagamento.
8. Cenários Futuros (2026-2030)
Baseado nas tendências atuais, projetam-se três cenários para a evolução desse ecossistema.
8.1 A “Wikipedização” Total da Infraestrutura
Neste cenário, a Wikipedia se torna a camada de “sistema operacional” de conhecimento da web. Interfaces diretas (sites) tornam-se obsoletas. A marca “Wikipedia” desaparece para o usuário final, dissolvida dentro da Siri, Alexa e ChatGPT. A sustentabilidade financeira é garantida inteiramente pelas taxas de licenciamento da Enterprise, transformando a fundação em uma reguladora de fatos para a indústria de tecnologia.
8.2 O Renascimento dos Jardins Murados (Paywalls)
Se a Britannica vencer o processo contra a Perplexity, estabelece-se que treinar IA em conteúdo protegido requer licença. Isso levaria a uma fragmentação da web. O New York Times, a Britannica, a Barsa e grandes editoras criariam silos de dados inacessíveis para IAs gratuitas. IAs de alta qualidade seriam extremamente caras, exclusivas para corporações e governos, enquanto o público geral teria acesso a IAs “burras” ou desatualizadas.
8.3 A Soberania de Dados Nacionais
Governos como o do Brasil podem intervir para garantir que IAs nacionais sejam treinadas em dados culturalmente relevantes. A Barsa/Planeta poderia se tornar parceira estratégica do Estado para fornecer o dataset de treinamento de uma “IA Soberana Brasileira”, garantindo que a inteligência artificial usada em escolas públicas conheça a história e a cultura do país sem o viés norte-americano
9. O Acervo Corporativo como Infraestrutura Epistêmica: Chatbots Empresariais e a Nova Economia da Verdade Interna
A mesma mutação estrutural que deslocou o centro de gravidade da web — da “disputa por atenção” para a “disputa pela integridade factual” — ocorre, em escala silenciosa, dentro das empresas. Se, no espaço público, enciclopédias e plataformas de conhecimento passaram a funcionar como lastro para conter a alucinação dos LLMs, no espaço corporativo o papel equivalente é exercido por um ativo historicamente subestimado: o acervo interno. Manuais de produto, padrões de engenharia, normas internas, políticas de compliance, relatórios de sustentabilidade, atas de comitês, lições aprendidas de projetos, missão, propósito e planejamento estratégico deixam de ser apenas documentos. Passam a ser, na prática, uma camada de realidade organizacional — a infraestrutura epistêmica que impede que a decisão cotidiana se degrade em improviso, ruído e contradição.
9.1 A Crise Epistêmica Dentro do Escritório
A empresa moderna é um organismo que produz conhecimento continuamente, mas raramente o organiza com a mesma disciplina com que organiza seu balanço financeiro. O resultado é um paradoxo conhecido de qualquer operação madura: quanto mais conteúdo existe, mais difícil é encontrar o “conteúdo certo”; quanto mais normas e procedimentos são publicados, mais provável é que alguém execute a versão antiga. A fricção informacional vira custo: atrasos, retrabalho, decisões divergentes entre áreas, risco de não conformidade, erosão de qualidade e insegurança jurídica.
A chegada dos LLMs introduz um novo atalho — e um novo perigo. O atalho é a promessa de acesso instantâneo ao conhecimento. O perigo é o mesmo da esfera pública: sistemas probabilísticos não “sabem” o que é verdade. Sem lastro, eles apenas soam convincentes. E, no universo corporativo, uma alucinação não é um erro acadêmico: é uma não conformidade, um incidente de segurança, uma proposta mal precificada, um parecer desalinhado, uma decisão técnica fora do padrão. A organização percebe, então, que o problema não é ter IA; o problema é ter IA sem uma âncora.
9.2 Do “FAQ de Atendimento” ao Produto de Governança
É nesse ponto que o chatbot corporativo se separa do folclore tecnológico. Um chatbot empresarial, quando tratado como brinquedo, vira um FAQ bem falante. Quando tratado como ativo estratégico, ele se torna outra coisa: um mecanismo de acesso governado ao acervo, capaz de transformar documentação dispersa em resposta operacional consistente. Ele não é uma máquina de redação. Ele é uma máquina de alinhamento.
O valor não nasce do texto gerado, mas do modelo de confiança que o sustenta: acesso restrito por perfil, curadoria de fontes oficiais, controle de versão, trilhas de auditoria, transparência de origem e políticas explícitas de “não responder” quando a pergunta sai do escopo. Em linguagem corporativa: o chatbot deixa de ser um canal e passa a ser um produto interno com SLA de verdade — uma camada que converte conhecimento formal em execução padronizada.
9.3 A Técnica como Economia: quando RAG vira “cadeia de custódia” da informação
Na arquitetura contemporânea, o caminho para essa confiabilidade é conhecido: o modelo precisa responder ancorado em uma base controlada, recuperando trechos do acervo e gerando a resposta a partir deles. Isso não é detalhe técnico; é a tradução concreta de uma demanda econômica e reputacional. Assim como a Wikipedia monetiza a garantia de origem e atualização para clientes que precisam de dados limpos e estruturados, a corporação passa a monetizar internamente seu próprio acervo — não com cobrança, mas com produtividade e redução de risco. A empresa compra de si mesma, diariamente, a capacidade de decidir com coerência.
O que muda é o status do documento. Um manual de engenharia não é mais “algo que existe em uma pasta”. Ele vira um componente vivo de uma cadeia de custódia informacional: quem escreveu, quando aprovou, qual versão está vigente, que processos dependem dele e quais respostas o chatbot está autorizado a derivar. O acervo, enfim, deixa de ser arquivo: torna-se infraestrutura.
9.4 OKRs e KPIs: o fim do “projeto de IA” e o nascimento de uma operação mensurável
A consequência inevitável dessa visão é a profissionalização do chatbot. Se ele é produto, precisa de metas. Se ele é infraestrutura, precisa de governança. O chatbot corporativo precisa alinhar objetivos e medir impacto com a mesma disciplina com que uma área mede custo, prazo e qualidade. Em termos práticos, o sucesso deixa de ser “temos um bot” e passa a ser: reduzimos tempo de busca, aumentamos taxa de autoatendimento, diminuímos retrabalho, reduzimos incidentes de compliance, padronizamos decisões técnicas, aceleramos onboarding, melhoramos a eficiência de processos e diminuímos o custo de coordenação entre áreas.
Nessa lógica, OKRs deixam de ser um ornamento de planejamento e viram o motor do produto: objetivos claros (adoção, qualidade, risco, produtividade) e resultados-chave observáveis (resolução, escalonamentos, satisfação, cobertura do acervo, frequência de gaps). A empresa sai do discurso e entra no regime de execução.
9.5 Propostas comerciais, risco e processo: o ganho invisível que sustenta a competitividade
O benefício mais subestimado de um chatbot corporativo ancorado no acervo é o ganho de consistência — especialmente em ambientes onde decisões técnicas e comerciais se cruzam. Em propostas comerciais, uma variação de premissa pode virar perda financeira; uma interpretação divergente pode gerar contrato frágil; um uso inadequado de linguagem pode expor a empresa. O chatbot, quando alimentado por normas internas, modelos aprovados, critérios de precificação e política de risco, funciona como estabilizador: reduz divergência, preserva coerência, sustenta qualidade e acelera respostas, sem romper compliance.
O mesmo vale para melhoria de processos. Ao registrar o que as pessoas perguntam — e, principalmente, o que o acervo não consegue responder — o chatbot se torna um radar de ineficiência. Cada lacuna recorrente é um indicador: ou o processo é confuso, ou a norma está mal escrita, ou a informação está desatualizada, ou o treinamento falhou. A telemetria do chatbot vira diagnóstico organizacional. A empresa, então, não apenas responde melhor: aprende melhor.
9.6 O exemplo aplicado: nMentors Academy e o Chatbot no CPFL nas Universidades
Foi nessa lógica — acervo como lastro, IA como camada de acesso, governança como diferenciação — que a nMentors Academy desenvolveu o chatbot no projeto CPFL nas Universidades. O desafio não era “ter IA”. O desafio era lidar com a complexidade natural de um programa com múltiplos conteúdos, instrumentos, metodologias e expectativas, garantindo que o conhecimento circulasse com consistência, sem depender de poucos especialistas ou de buscas manuais em repositórios.
O chatbot foi concebido como uma peça de infraestrutura educacional e operacional: um ponto de acesso para orientar navegação, esclarecer dúvidas, direcionar o usuário ao material correto, reduzir fricção e sustentar uma experiência de aprendizagem mais fluida. Ao mesmo tempo, por operar em um contexto institucional, o desenho respeitou o princípio fundamental da economia da verdade: não basta responder; é preciso responder com lastro, dentro do escopo, com rastreabilidade. O valor entregue não foi “uma interface simpática”, mas um mecanismo de confiabilidade em escala.
9.7 Por que isso se tornou um serviço corporativo inevitável
Toda empresa que depende de normas, engenharia, compliance e consistência precisa transformar seu acervo em uma camada operacional acessível. A alternativa é continuar pagando o imposto invisível da fricção informacional: horas perdidas, retrabalho, desalinhamento, risco e decisões divergentes. A promessa de um chatbot corporativo não é futurismo. É governança aplicada à produtividade.
A nMentors Academy, ao endereçar esse tipo de implantação, não vende “um bot”. Vende um projeto de transformação do acervo em ativo executável: curadoria, taxonomia, acesso restrito, operação com métricas, melhoria contínua, e, sobretudo, a capacidade de traduzir missão, propósito e estratégia em orientação prática do dia a dia. É a passagem do conhecimento como patrimônio para o conhecimento como operação.
E, como aconteceu com as enciclopédias na esfera pública, o resultado final é o mesmo: na era em que a inteligência artificial fala com convicção sobre qualquer coisa, o diferencial competitivo deixa de ser “falar”. Passa a ser “falar com verdade”. Dentro das corporações, isso tem outro nome: governança. E sua materialização mais eficiente, hoje, é um chatbot corporativo ancorado no acervo que a própria organização levou décadas para construir.
10. Conclusão
A iniciativa da Wikipedia de treinar chatbots não é uma capitulação aos gigantes da tecnologia, mas uma manobra de sobrevivência calculada e necessária. Ao cobrar das Big Techs pelo acesso estruturado, a Wikimedia Foundation garante que o “comum digital” não seja exaurido pela exploração comercial privada, convertendo a infraestrutura de conhecimento em receita recorrente e, com isso, preservando a gratuidade e a continuidade do ecossistema.
Simultaneamente, a reação da Encyclopædia Britannica e da Barsa demonstra que, na era da alucinação artificial, credibilidade humana e responsabilidade editorial tornaram-se ativos raros, defensáveis e monetizáveis. A Britannica aposta no litígio e em produtos proprietários para proteger a integridade de sua marca e o valor econômico do seu acervo; a Barsa, por sua vez, se ancora na especificidade cultural e no alinhamento pedagógico brasileiro como forma de manter relevância e autoridade em um mercado institucional que valoriza controle, curadoria e previsibilidade.
O ponto decisivo, contudo, é que essa “economia da verdade” não se limita ao espaço público das enciclopédias e dos motores de busca. Ela se desloca para dentro das organizações. À medida que LLMs passam a mediar decisões e respostas, o acervo corporativo — manuais de produto, padrões de engenharia, normas internas, compliance, lições aprendidas, missão, propósito, planejamento estratégico e relatórios de sustentabilidade — deixa de ser documentação passiva e se torna infraestrutura epistêmica interna: o lastro que protege a empresa da improvisação, da divergência entre áreas e do risco operacional. O Chatbot corporativo, quando ancorado em acesso restrito e governança, não é um FAQ sofisticado; é um mecanismo de alinhamento em escala, capaz de traduzir conhecimento formal em execução consistente, medir impacto por OKRs/KPIs e transformar lacunas informacionais em melhoria contínua de processos.
Nesse sentido, projetos como o desenvolvido pela nMentors Academy no CPFL nas Universidades ilustram a transposição prática do mesmo princípio que sustenta Wikipedia, Britannica e Barsa: não basta gerar respostas; é preciso garantir origem, contexto e confiabilidade. A promessa de valor não está na eloquência da máquina, mas na disciplina do acervo, na curadoria humana e na governança que delimita escopo, reduz alucinações e converte conhecimento em produtividade, eficiência e mitigação de risco — com rastreabilidade.
O futuro da informação, portanto, não reside na capacidade das máquinas de gerar texto, mas na capacidade das instituições humanas de verificar, versionar e sustentar a verdade — seja para o público, seja para suas próprias operações. As enciclopédias evoluíram de repositórios para âncoras de realidade; as empresas, agora, são compelidas a fazer o mesmo com sua memória institucional. Para a sociedade, o desafio permanece político e econômico: garantir que esse “lastro de verdade” não se torne um privilégio de quem pode pagar por infraestruturas Enterprise. Para as corporações, o desafio é executivo: reconhecer que, na era dos LLMs, governança do conhecimento não é custo administrativo — é vantagem competitiva.