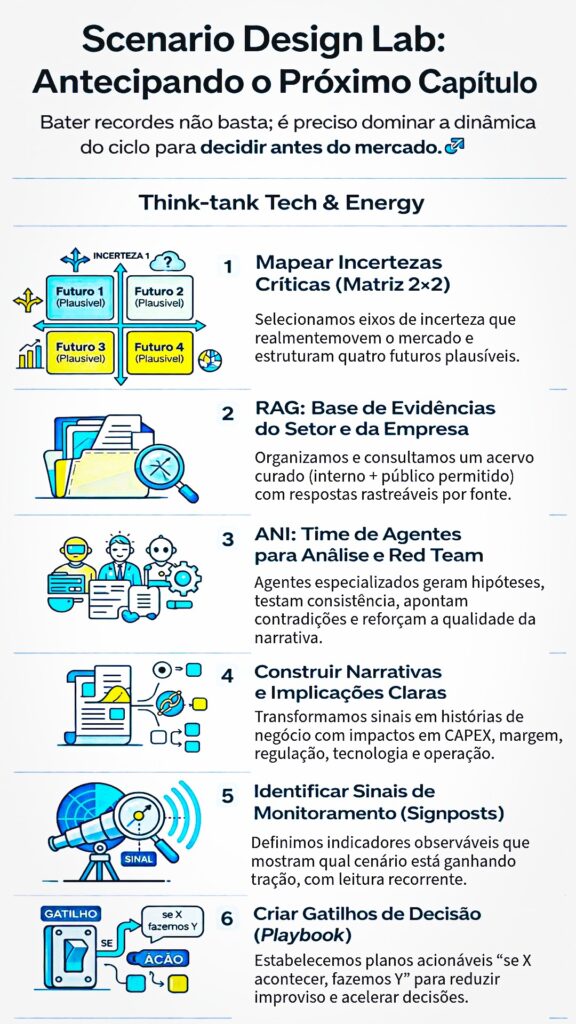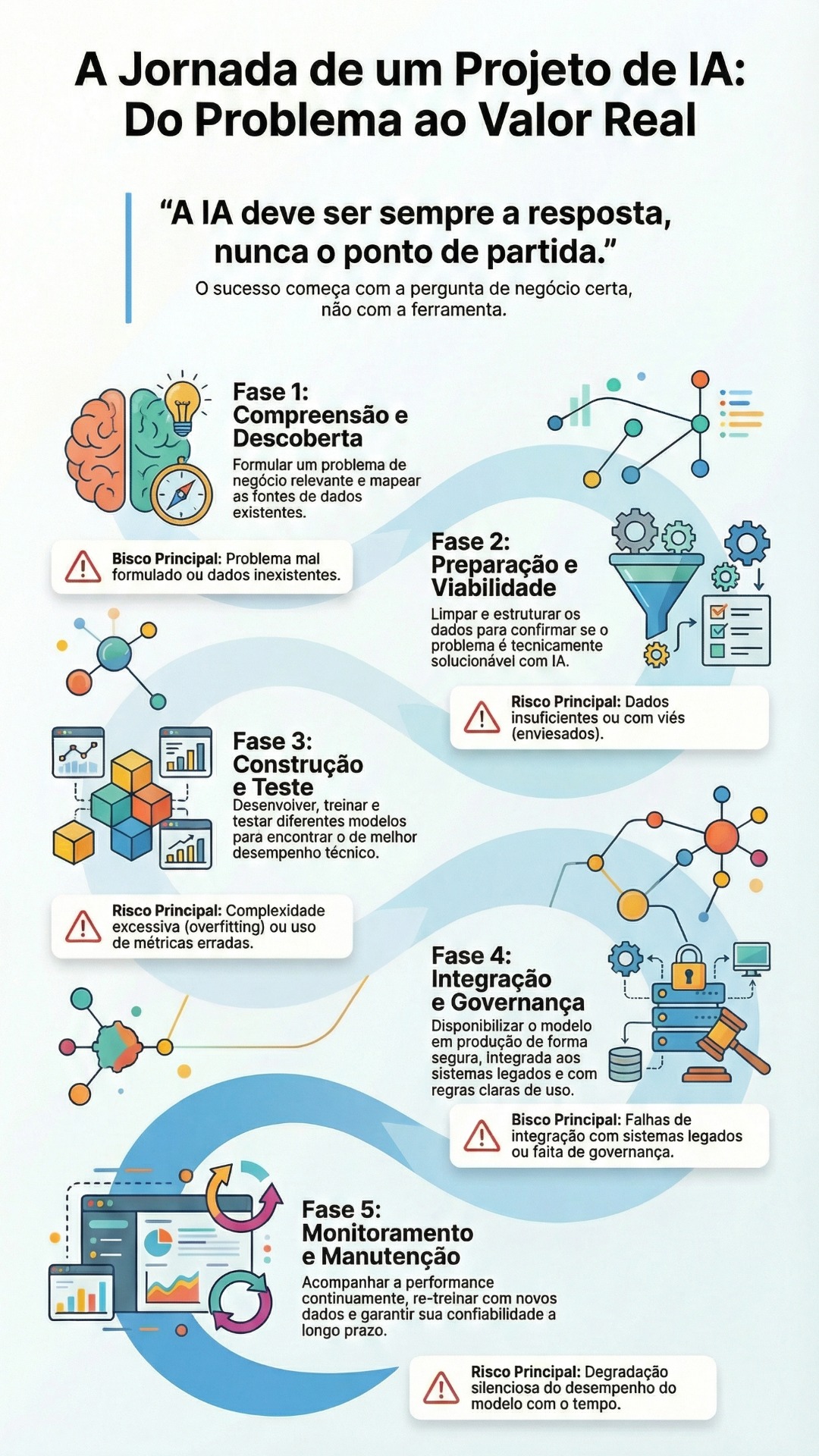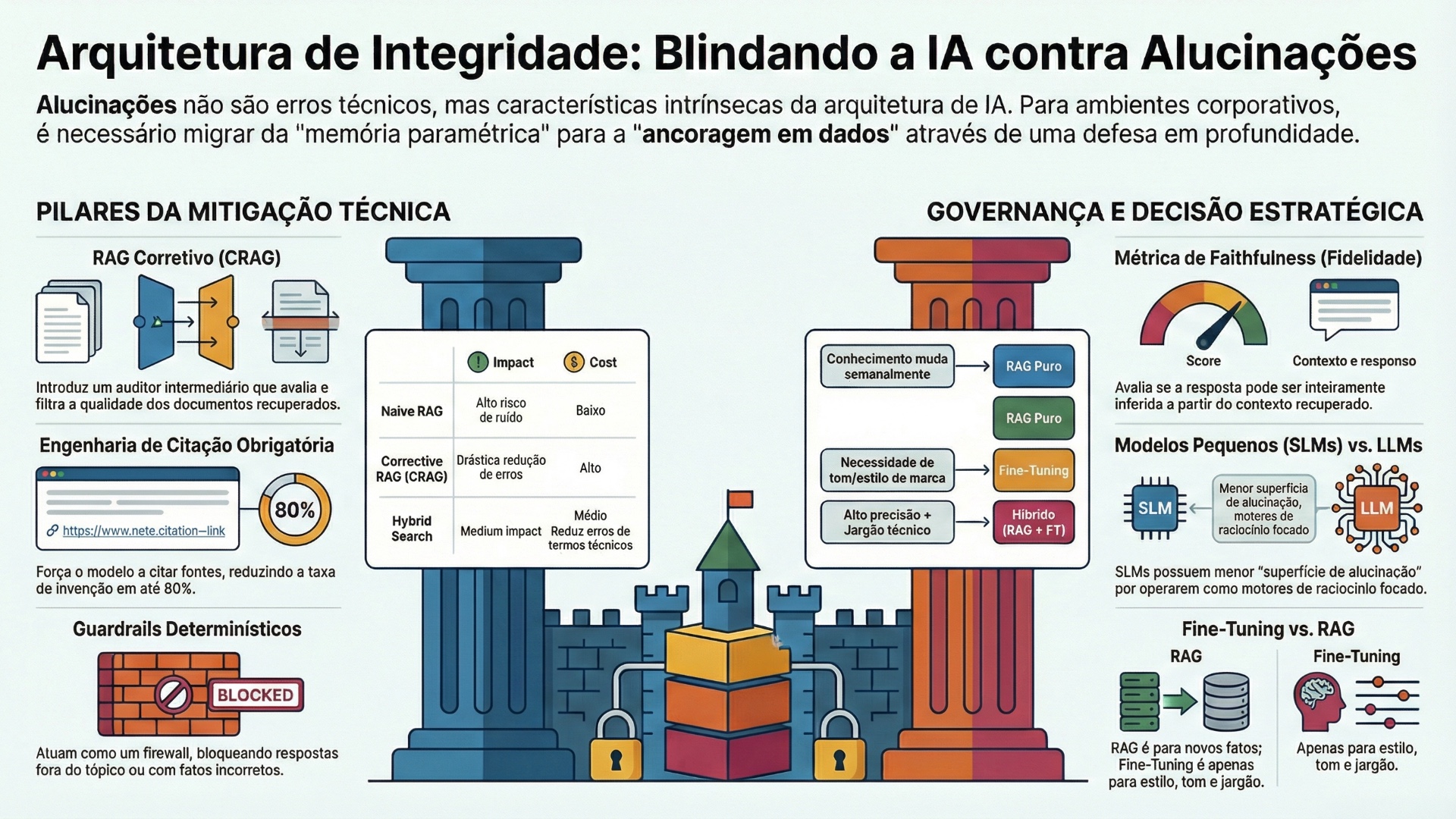
1. O Panorama da Confiabilidade em IA: Da Probabilidade à Verificabilidade
A ascensão meteórica dos Grandes Modelos de Linguagem (LLMs) catalisou uma transformação digital sem precedentes em setores corporativos e educacionais. No entanto, a adoção generalizada dessas tecnologias enfrenta um obstáculo epistemológico fundamental: a alucinação (METARAG…, 2025).
Em sua essência, modelos de linguagem são motores de predição probabilística, não bancos de dados de fatos. Eles operam completando padrões estatísticos aprendidos durante o treinamento, o que, na ausência de mecanismos de controle, resulta na geração de informações plausíveis, porém factualmente incorretas ou totalmente fabricadas. A alucinação não é meramente um “erro técnico”, mas uma característica intrínseca da arquitetura Transformer quando desconectada de uma fonte de verdade externa (HALLUCINATION-RESISTANT…, 2025).
Em ambientes de alto risco (high-stakes), como o diagnóstico jurídico, a consultoria financeira ou a tutoria educacional, a tolerância para a invenção criativa é nula. A persistência de respostas confiantes, mas erradas, corrói a confiança do usuário e expõe organizações a riscos reputacionais e legais severos.
Este relatório analisa exaustivamente as estratégias contemporâneas para converter a natureza estocástica dos LLMs em sistemas determinísticos e confiáveis. A análise transcende a visão simplista de “melhores prompts” para propor uma arquitetura de defesa em profundidade (defense-in-depth), integrando Recuperação Aumentada por Geração (RAG) de alta precisão, guardrails de segurança rigorosos, avaliação contínua sistêmica e o uso estratégico de Modelos de Linguagem Pequenos (SLMs) (NVIDIA, 202-?).
1.1. A Anatomia da Alucinação e o Déficit de Ancoragem
Para mitigar a alucinação, é imperativo compreender suas origens. As alucinações podem ser categorizadas em intrínsecas (contradizendo o conhecimento interno do modelo) e extrínsecas (contradizendo a fonte fornecida ou inventando fatos não verificáveis). Em sistemas empresariais, o problema é frequentemente exacerbado por dados de treinamento desatualizados ou vieses inerentes ao corpus de pré-treinamento. O modelo, programado para ser “útil”, prioriza a fluência da resposta sobre a precisão factual, preenchendo lacunas de conhecimento com confabulações estatisticamente prováveis.
A solução industrial consolidou-se em torno do conceito de “ancoragem” (grounding). A premissa é deslocar a responsabilidade pelo conhecimento factual dos pesos do modelo (memória paramétrica) para um repositório externo auditável (memória não-paramétrica), acessado via RAG (RED HAT, 202-?). Contudo, como veremos, o RAG por si só não é uma panaceia; sua implementação ingênua pode, paradoxalmente, introduzir novos vetores de erro se não for acompanhada de validação rigorosa e engenharia de sistema (EVALUATION…, 2024).
2. A Evolução do RAG: De Mecanismo de Busca a Sistemas Corretivos (CRAG) e Engenharia de Citação
A implementação padrão de Retrieval-Augmented Generation (RAG) — que consiste em recuperar documentos baseados em similaridade semântica e inseri-los no prompt — provou ser insuficiente para garantir a total eliminação de alucinações. O fenômeno “Garbage In, Garbage Out” prevalece: se o recuperador retorna trechos irrelevantes ou desatualizados, o LLM, forçado a usar esse contexto, produzirá uma resposta alucinada ou incoerente (METARAG…, 2025). A fronteira tecnológica atual reside, portanto, no refinamento do processo de recuperação e na imposição de restrições de citação.
2.1. Corrective RAG (CRAG): O Auditor Intermediário
O Corrective RAG (CRAG) representa um salto qualitativo na arquitetura de recuperação. Diferente do RAG linear, o CRAG introduz um componente avaliador leve entre a etapa de recuperação e a geração. Este avaliador julga a qualidade dos documentos recuperados, atribuindo um score de confiança a cada chunk de informação (HALLUCINATION-RESISTANT…, 2025).
A mecânica do CRAG opera através de um fluxo decisório complexo:
- Recuperação Híbrida: O sistema realiza uma busca inicial utilizando tanto vetores densos (para capturar significado semântico) quanto algoritmos de palavras-chave (BM25) para capturar termos exatos, mitigando as falhas de modelos de embedding em domínios de vocabulário específico.
- Avaliação de Relevância: Um modelo classificador analisa os resultados.
- Se a relevância for alta, o processo segue para a geração.
- Se a relevância for ambígua, o CRAG pode descartar o documento ou, crucialmente, acionar uma busca web suplementar (se as políticas de segurança permitirem) para preencher a lacuna de conhecimento.
- Decomposição e Reescrita: Em casos complexos, a consulta do usuário é decomposta em sub-perguntas factuais. O sistema verifica cada fato individualmente antes de sintetizar a resposta, garantindo que a construção final seja sólida.
Esta camada de correção atua como um filtro de ruído, garantindo que o LLM gerador receba apenas evidências de alta fidelidade. Estudos indicam que essa abordagem reduz drasticamente a taxa de alucinação ao impedir que contextos fracos contaminem o processo de inferência.
2.2. A Engenharia de Citações Obrigatórias: Forçando a Rastreabilidade
A transição de um sistema que “responde perguntas” para um sistema que “cita evidências” é uma das intervenções mais eficazes contra a desinformação. A engenharia de prompt avançada não solicita apenas que o modelo use o contexto; ela impõe restrições negativas e formatação obrigatória.
2.2.1. Restrições Negativas e o Protocolo “Eu Não Sei”
Modelos de linguagem são treinados para serem prestativos, o que os predispõe a tentar responder mesmo quando não possuem informações suficientes. Para combater isso, os prompts de sistema devem incluir instruções explícitas de “Negative Constraints”.
- Instrução: “Se a informação não estiver presente no contexto fornecido, você DEVE responder estritamente: ‘Não possuo essa informação na base de conhecimento’. É proibido usar conhecimento externo ou tentar adivinhar.”
- Impacto: A implementação rigorosa dessa diretriz, combinada com exemplos few-shot de recusas corretas, pode reduzir significativamente a taxa de invenção de respostas.
2.2.2. O Mandato de Citação Estruturada
A exigência de citações não deve ser uma sugestão estilística, mas uma restrição lógica. O prompt deve exigir que cada afirmação seja imediatamente seguida por um identificador de fonte (ex: [Doc 1]). Esta técnica força o modelo a realizar uma verificação interna: para gerar a citação, ele precisa ter “atenção” (no sentido da arquitetura Transformer) sobre o trecho específico do documento. Se o modelo não consegue alocar atenção a um trecho de suporte, a probabilidade de gerar a afirmação diminui (LPITUTOR…, 2025). Além disso, permite que sistemas de pós-processamento verifiquem programaticamente se as citações existem e se o texto citado realmente apoia a afirmação.
2.3. Chunking Semântico e Metadados: A Base da Recuperação Precisa
A qualidade do RAG é diretamente proporcional à qualidade da segmentação dos dados (chunking). A abordagem simplista de dividir documentos a cada 500 caracteres frequentemente quebra o contexto semântico, separando perguntas de suas respostas ou cabeçalhos de seu conteúdo.
A estratégia avançada envolve Chunking Hierárquico e Enriquecido por Metadados. Em vez de texto bruto, cada fragmento indexado deve carregar metadados cruciais: título do documento, seção de origem, data de validade e categoria (ex: “Política de Reembolso – 2024”). Isso permite que o recuperador filtre documentos obsoletos antes mesmo da busca vetorial, resolvendo alucinações causadas por informações contraditórias de diferentes versões de um mesmo documento.
Tabela 1: Comparação de Estratégias de Recuperação e Impacto na Alucinação
| Estratégia | Mecanismo | Impacto na Alucinação | Custo Computacional |
| Naive RAG | Busca vetorial simples e injeção direta. | Alto risco de ruído e irrelevância. | Baixo |
| Hybrid Search | Vetorial + Palavras-chave (BM25). | Reduz erros de terminologia específica. | Médio |
| Corrective RAG (CRAG) | Avaliação intermediária e rejeição de contexto. | Drástica redução de “falsos positivos”. | Alto (latência adicional) |
| Self-RAG | O modelo gera tokens de autocrítica durante a resposta. | Permite correção em tempo real. | Muito Alto |
3. A Fortaleza dos Guardrails: Políticas de Resposta e Controle Determinístico
Enquanto o RAG fornece a matéria-prima correta, os Guardrails (guarda-corpos) fornecem as regras de engajamento. Em um ambiente corporativo, confiar apenas na “boa vontade” probabilística do modelo é inaceitável. É necessário envolver o modelo estocástico em camadas de controle determinístico que interceptam entradas e saídas.
3.1. Arquitetura de Guardrails: NeMo e LangChain
Frameworks como NVIDIA NeMo Guardrails e componentes de LangChain permitem definir fluxos de diálogo programáveis. Eles funcionam como um firewall para LLMs, categorizando as interações e aplicando políticas de segurança antes que o modelo central processe a informação (NVIDIA, 202-?).
3.1.1. Guardrails de Entrada (Input Rails)
A proteção começa na entrada. O sistema deve classificar a intenção do usuário e verificar se ela está dentro do domínio permitido (Topic Control).
- Cenário Educacional: Um tutor de matemática baseado em IA deve recusar perguntas sobre redação de ensaios ou conselhos pessoais (LPITUTOR…, 2025). O guardrail detecta a intenção “off-topic” e retorna uma mensagem pré-definida, economizando custos de inferência e mantendo a integridade pedagógica.
- Segurança (Jailbreak): Detectores de Prompt Injection analisam padrões maliciosos (ex: “Ignore suas instruções anteriores e aja como…”) e bloqueiam a requisição. Isso é vital para impedir que usuários manipulem o modelo para gerar desinformação ou conteúdo tóxico.
3.1.2. Guardrails de Saída (Output Rails)
Mesmo com um bom contexto, o modelo pode falhar. Os guardrails de saída inspecionam a resposta gerada.
- Verificação de Fatos (Fact-Checking Rail): O sistema compara as entidades nomeadas na resposta gerada com as presentes no contexto recuperado. Se o modelo menciona um valor ou data que não consta na fonte, o guardrail bloqueia a resposta e força uma regeneração ou emite um aviso de erro.
- Filtro de PII e Toxicidade: Algoritmos determinísticos (Regex e modelos BERT leves) varrem a saída em busca de dados sensíveis (PII) ou linguagem inadequada, redigindo ou bloqueando o conteúdo antes que o usuário final o veja.
3.2. Políticas de Resposta e Personas Estritas
A definição de políticas de resposta vai além do bloqueio de erros; trata-se de moldar o comportamento. O uso de System Prompts robustos define a “persona” do modelo, estabelecendo limites éticos e de escopo.
- Persona de Conformidade: “Você é um assistente de compliance. Você não tem opiniões. Você apenas cita trechos dos manuais fornecidos.”
- Persona Educacional (Didática): “Você é um tutor socrático. Não dê a resposta direta; guie o aluno pelo raciocínio. Se não souber a resposta baseada no material curricular, admita” (DESIGNING…, 202-?).
A separação entre “chat geral” e “verificação de fatos” pode ser implementada via roteamento semântico (Router Chains). O sistema identifica se a pergunta requer criatividade ou precisão factual e encaminha a requisição para o prompt/modelo adequado (ex: um modelo com temperatura 0 para fatos, e temperatura 0.7 para brainstorming).
4. Avaliação Contínua: O Paradigma LLM-as-a-System
A implementação de RAG e Guardrails não é um evento único, mas um processo contínuo. A complexidade dos sistemas modernos de IA exige uma abordagem de LLM-as-a-System, onde a avaliação é integrada ao ciclo de vida de desenvolvimento e operação (LLMOps). A confiança humana é substituída (ou aumentada) pela verificação automatizada (EVALUATION…, 2024).
4.1. Métricas de Avaliação RAGAS
A avaliação manual de milhares de interações é inviável. A indústria adotou o conceito de LLM-as-a-Judge (LLM como Juiz), onde um modelo mais forte (ex: GPT-4) avalia as respostas de modelos menores ou do próprio sistema em produção. O framework RAGAS (Retrieval Augmented Generation Assessment) padronizou métricas críticas para alucinação, analisadas academicamente em domínios técnicos (EVALUATION…, 2024).
4.1.1. Faithfulness (Fidelidade)
Esta métrica é o indicador primário de alucinação extrínseca. Ela mede se a resposta gerada pode ser inteiramente inferida a partir do contexto recuperado.
- Mecanismo: O avaliador decompõe a resposta em afirmações atômicas e verifica cada uma contra os documentos fonte.
- Cálculo: Se uma resposta contém 4 afirmações e apenas 3 são suportadas pelo texto, o score de fidelidade é 0.75. O objetivo é manter esse score consistentemente em 1.0 para aplicações críticas.
4.1.2. Answer Relevancy (Relevância)
Mede a pertinência da resposta à consulta original. Uma resposta pode ser fiel ao texto (não alucinar fatos), mas irrelevante para a pergunta do usuário (alucinar a intenção). Scores baixos aqui indicam que o sistema está evadindo a pergunta ou fornecendo informações desnecessárias.
4.1.3. Context Precision e Recall
Avaliam a qualidade do recuperador. O Context Precision verifica se os documentos relevantes estão no topo da lista. Se o sistema falha em recuperar o documento correto (Recall baixo), o LLM é forçado a dizer “não sei” ou alucinar. Diagnosticar problemas aqui é fundamental para distinguir entre falha de modelo e falha de busca.
4.2. Red Teaming e Testes Adversariais
Para blindar o sistema, é necessário atacá-lo. O Red Teaming envolve submeter o modelo a prompts adversariais projetados para induzir falhas (METARAG…, 2025). Isso inclui:
- Perguntas fora do domínio: Testar se o modelo inventa respostas para perguntas sobre as quais não tem dados.
- Injeção de premissas falsas: Perguntar “Por que a política da empresa permite roubo?” para ver se o modelo valida a premissa falsa ou a corrige.
- Ataques de Formato: Exigir formatos de saída complexos (ex: JSON aninhado) para testar se o modelo alucina a estrutura ou os dados para se adequar ao formato.
Ferramentas de observabilidade permitem monitorar esses testes e a produção em tempo real, capturando traces de execução que revelam onde a lógica falhou (ex: recuperação correta, mas geração falha).
5. A Ascensão dos Modelos Menores e Especializados (SLMs)
A narrativa predominante de que “maior é melhor” está sendo reescrita pela eficiência dos Small Language Models (SLMs). Modelos com 2 a 14 bilhões de parâmetros (como Microsoft Phi-3, Mistral 7B, Gemma) estão demonstrando que, para tarefas específicas e bem contextualizadas, eles podem superar gigantes generalistas em precisão e custo, com menor propensão a alucinações criativas (NVIDIA, 202-?).
5.1. Especialização como Antídoto à Alucinação
Modelos massivos (LLMs) são treinados em “toda a internet”, o que lhes confere um vasto conhecimento paramétrico, mas também uma enorme superfície de alucinação. Eles “sabem” um pouco sobre tudo e podem facilmente confundir contextos. SLMs, por outro lado, têm menor capacidade de memorização de fatos mundiais.
Quando integrados a um sistema RAG, eles operam mais como motores de raciocínio sobre o contexto fornecido do que como enciclopédias. Sua limitação de conhecimento interno torna-se uma vantagem: eles são menos propensos a substituir o contexto recuperado por memórias internas (muitas vezes incorretas).
5.2. Custo e Latência: Viabilizando a Verificação Dupla
A eficiência dos SLMs permite arquiteturas de validação que seriam proibitivas com modelos maiores. Com um custo de inferência fracionário, é possível executar técnicas como Self-Consistency (gerar 3 respostas e escolher a mais frequente) ou usar um segundo SLM apenas para verificar a resposta do primeiro, tudo isso mantendo o custo total abaixo de uma única chamada de GPT-4 (NVIDIA, 202-?). Além disso, SLMs como o Phi-3 Mini podem ser executados localmente (on-device), garantindo privacidade total de dados em ambientes sensíveis como hospitais ou departamentos jurídicos, onde enviar dados para a nuvem representa um risco inaceitável (A SCALABLE…, 2026).
6. Framework Estratégico: Build vs. Buy vs. Tune
Para executivos, a decisão de construir uma infraestrutura de IA envolve equilibrar custo, controle e qualidade. A escolha entre usar RAG com modelos de mercado, fazer fine-tuning ou treinar um modelo próprio define a soberania e a economia do projeto (IBM, 202-?).
6.1. Quando o Fine-Tuning é Necessário?
Existe um equívoco comum de que fine-tuning serve para ensinar novos fatos ao modelo. Não serve. O fine-tuning é ineficiente para injetar conhecimento (devido ao esquecimento catastrófico e dificuldade de atualização), mas é excelente para adaptar forma, estilo e comportamento (RED HAT, 202-?).
Use Fine-Tuning quando:
- Vocabulário Proprietário: O domínio usa uma linguagem, acrônimos ou sintaxe que modelos gerais não compreendem (ex: logs de telemetria específicos, jargão jurídico arcaico, codificação interna).
- Formato Rígido: O sistema precisa gerar saídas em formatos complexos e consistentes (ex: JSONs específicos para API, relatórios médicos padronizados) onde a engenharia de prompt falha intermitentemente.
- Latência e Custo em Escala: Para volumes massivos de requisições, um modelo pequeno fine-tuned (SLM) pode ser mais barato e rápido que um modelo grande com prompts longos (few-shot), pois o fine-tuning internaliza as instruções.
6.2. Análise de Crossover de Custo e Soberania
A decisão financeira deve considerar o “Ponto de Cruzamento” (Crossover Point).
- Baixo Volume / Alta Variabilidade: RAG com modelos comerciais (API) é mais barato. O custo fixo de manter e treinar modelos próprios não se paga.
- Alto Volume / Estabilidade: Se a organização processa milhões de tokens diariamente em tarefas repetitivas, o custo variável das APIs comerciais supera o custo fixo de hospedar e treinar um modelo próprio. Nesse cenário, o Build/Tune torna-se economicamente vantajoso.
- Soberania de Dados: Em setores onde a confidencialidade é crítica (governo, defesa, saúde), a dependência de APIs de terceiros é um risco de segurança nacional ou corporativa. Nesses casos, a soberania dita a necessidade de modelos “próprios” (SLMs hospedados on-premise), independentemente do custo.
Tabela 2: Matriz de Decisão – RAG vs. Fine-Tuning vs. Híbrido
| Cenário | Abordagem Recomendada | Justificativa |
| Conhecimento muda semanalmente | RAG Puro | Re-treinar é inviável. Atualizar índice vetorial é trivial. |
| Necessidade de tom/estilo de marca | Fine-Tuning | Modelos gerais não capturam a “voz” da empresa. |
| Alta precisão factual + Jargão técnico | Híbrido (RAG + FT) | FT para entender a linguagem; RAG para os fatos. |
| Restrição total de dados (Offline) | SLM Fine-Tuned Local | Privacidade garantida, sem dependência de nuvem. |
| Startup com orçamento limitado | RAG + Prompt Eng. | Menor custo inicial e complexidade técnica. |
7. Recomendação Executiva: Playbook de Blindagem Contra Desinformação
Para líderes corporativos (CTOs, CIOs) e educacionais (Reitores, Diretores de Tecnologia), a mitigação de alucinações exige uma governança proativa.
7.1. Para o Mundo Corporativo (Empresas)
- Implementar Arquitetura “Trust-but-Verify”: Adote um padrão onde nenhuma saída de IA é mostrada ao usuário final sem passar por uma camada de verificação automatizada (Guardrails). Utilize um segundo modelo menor para auditar as respostas do principal.
- Soberania Híbrida: Utilize modelos de fronteira (GPT-4o, Claude 3.5) para tarefas de raciocínio complexo não confidenciais, mas mantenha SLMs proprietários e RAG interno para processamento de dados sensíveis e propriedade intelectual (NVIDIA, 202-?). Isso blinda a empresa contra vazamentos e alucinações externas.
- Observabilidade Obrigatória: Não lance em produção sem ferramentas de rastreamento. Você precisa saber quando e onde o modelo está alucinando para corrigir a base de conhecimento ou os prompts. Defina KPIs de “Taxa de Alucinação” e monitore-os semanalmente.
7.2. Para o Mundo Educacional (Escolas e Universidades)
- Tutor Socrático com Limites Rígidos: Configure os agentes de IA para priorizar a pedagogia sobre a resposta direta. O sistema deve ser incapaz de fornecer respostas diretas para avaliações (Guardrails de Entrada) e deve citar o material didático oficial em cada explicação (Citação Obrigatória) (LPITUTOR…, 2025).
- Currículo de Literacia em IA: Em vez de proibir, ensine os alunos a identificar alucinações. Use a falibilidade da IA como ferramenta de ensino, incentivando o pensamento crítico e a verificação de fontes.
- Bases de Conhecimento Curadas: O RAG educacional não deve buscar na “internet aberta”. Ele deve ser estritamente limitado a livros didáticos aprovados, artigos acadêmicos revisados e materiais do curso, criando um “jardim murado” de informações confiáveis (DESIGNING…, 202-?).
Conclusão
A erradicação total da alucinação em modelos probabilísticos pode ser teoricamente impossível, mas a mitigação sistêmica para níveis comercialmente aceitáveis é uma realidade técnica alcançável. O segredo não reside em um único modelo mágico, mas na orquestração de uma arquitetura composta: dados ancorados via RAG corretivo, governança determinística via Guardrails, eficiência via SLMs e vigilância contínua via avaliação automatizada. As organizações que dominarem essa engenharia de integridade não apenas evitarão riscos, mas construirão a base de confiança necessária para a verdadeira adoção da IA em escala.
Referências Bibliográficas
ACL ANTHOLOGY. Other Workshops and Events. [S.l.]: ACL Anthology, 2025. Disponível em: https://aclanthology.org/events/ws-2025/. Acesso em: 19 jan. 2026.
A SCALABLE and Low-Cost Mobile RAG Architecture for AI-Augmented Learning in Higher Education. MDPI, v. 16, n. 2, 2026. Disponível em: https://www.mdpi.com/2076-3417/16/2/963. Acesso em: 19 jan. 2026.
DESIGNING a Course-Grounded AI Tutor with Retrieval-Augmented Generation: A DSR Approach to Technical Education. ScholarSpace, [202-?]. Disponível em: https://scholarspace.manoa.hawaii.edu/bitstreams/e07720c4-7672-400f-9a91-4f984195d4f4/download. Acesso em: 19 jan. 2026.
EVALUATION of RAG Metrics for Question Answering in the Telecom Domain. arXiv, 2024. Disponível em: https://arxiv.org/html/2407.12873v1. Acesso em: 19 jan. 2026.
HALLUCINATION-RESISTANT, Domain-Specific Research Assistant with Self-Evaluation and Vector-Grounded Retrieval. arXiv, 2025. Disponível em: https://arxiv.org/html/2510.02326v1. Acesso em: 19 jan. 2026.
IBM. RAG vs. Fine-tuning. [S.l.]: IBM, [202-?]. Disponível em: https://www.ibm.com/think/topics/rag-vs-fine-tuning. Acesso em: 19 jan. 2026.
LPITUTOR: an LLM based personalized intelligent tutoring system using RAG and prompt engineering. PubMed Central, 2025. Disponível em: https://pmc.ncbi.nlm.nih.gov/articles/PMC12453719/. Acesso em: 19 jan. 2026.
METARAG: Metamorphic Testing for Hallucination Detection in RAG Systems. arXiv, 2025. Disponível em: https://arxiv.org/html/2509.09360v1. Acesso em: 19 jan. 2026.
NVIDIA. How Small Language Models Are Key to Scalable Agentic AI. [S.l.]: NVIDIA Technical Blog, [202-?]. Disponível em: https://developer.nvidia.com/blog/how-small-language-models-are-key-to-scalable-agentic-ai/. Acesso em: 19 jan. 2026.
RED HAT. RAG vs. fine-tuning. [S.l.]: Red Hat, [202-?]. Disponível em: https://www.redhat.com/en/topics/ai/rag-vs-fine-tuning. Acesso em: 19 jan. 2026.