Em dezembro de 2025, uma reportagem do jornal O Estado de S. Paulo descreveu um episódio de interrupção relevante no fornecimento de energia na Grande São Paulo, após um evento climático severo. No mesmo contexto, registrou-se uma articulação institucional entre Ministério de Minas e Energia (MME), governo do Estado e prefeitura da capital para acionar a Agência Nacional de Energia Elétrica (Aneel) e iniciar trâmites regulatórios associados à concessão de distribuição. A matéria também reportou a coexistência de três elementos típicos em eventos desse tipo: efeitos operacionais prolongados para parte dos consumidores, mobilização e ações de recomposição pela distribuidora, e divergências sobre métricas e registros operacionais em temas como manutenção preventiva e podas preventivas.
Este caso é citado aqui apenas como referência para uma tese prática:
quando um data center decide onde se instalar, a análise não pode ficar restrita a preço e disponibilidade de energia, conectividade e condições imobiliárias.
A decisão precisa incorporar parâmetros de resiliência territorial e de governança operacional do ecossistema local. Em linguagem de comitê de investimentos, trata-se de reduzir risco de cauda (tail risk) e aumentar previsibilidade do serviço, algo que impacta diretamente SLA (Service Level Agreement), reputação, custo total de propriedade e expansão futura.
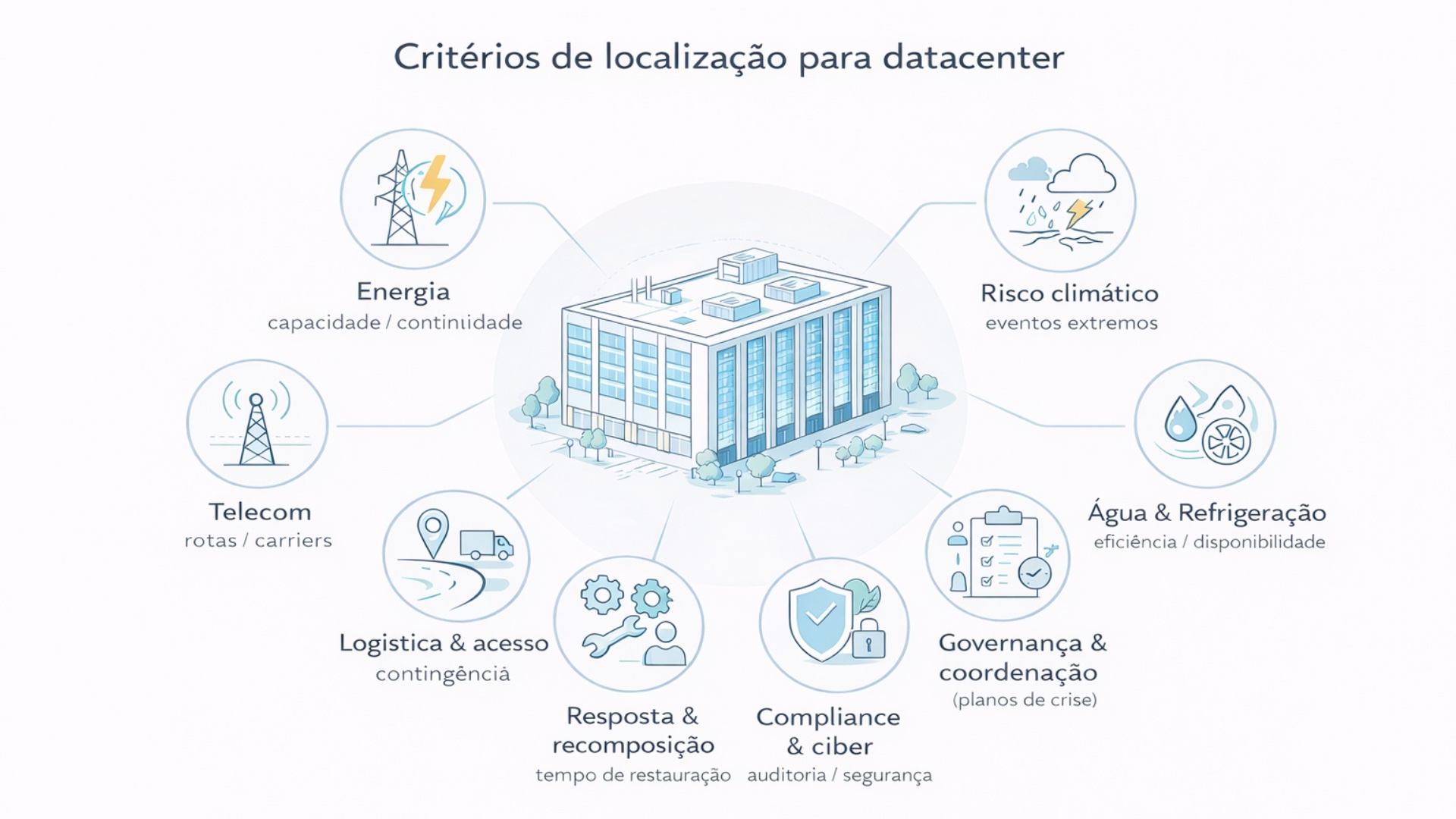
A localização de um data center deve ser tratada como um problema de infraestrutura crítica e gestão de risco sistêmico. O site não é um “ponto no mapa”. É um nó em uma rede de dependências: distribuição elétrica, transmissão, telecom, logística, gestão urbana, protocolos de crise, capacidade institucional e coordenação entre atores. O diferencial competitivo está em transformar variáveis frequentemente “invisíveis” em critérios objetivos, auditáveis e comparáveis entre cidades e regiões.
Em termos operacionais, a recomendação é adotar um modelo de diligência (due diligence) em duas camadas:
Camada 1: pré-requisitos técnicos clássicos
- Energia, telecom, imóvel/implantação, licenciamento e segurança física.
Camada 2: resiliência territorial e governança
- Qualidade histórica de continuidade do serviço, capacidade de resposta e recomposição, maturidade de gestão pública em crise, características urbanas que amplificam impactos (vegetação, drenagem, acesso), além de previsibilidade regulatória e institucional.
O resultado esperado é uma seleção de local que minimize surpresas, acelere implantação, sustente expansão e permita arquiteturas de alta disponibilidade mais eficientes (isto é, menos dependentes de “overdesign” caro para compensar incertezas do território).
O tripé clássico e o “quarto pilar” que costuma faltar
- Energia: A avaliação tradicional costuma priorizar capacidade de atendimento, custo marginal de energia, proximidade de subestações e viabilidade de conexão. Isso permanece necessário, porém insuficiente. Para data centers, energia também significa qualidade, continuidade e tempo de recomposição. A análise deve incluir indicadores e evidências.
- Telecom: A regra de ouro segue válida: diversidade real de rotas (não apenas diversidade de fornecedores), presença de múltiplos carriers, disponibilidade de backhaul, latência para pontos de troca e redundância física.
- Imóvel e implantação: Zoneamento, restrições ambientais, cronograma civil, riscos geotécnicos, acessibilidade logística e viabilidade de crescimento do campus.
- Resiliência territorial e governança: Aqui reside a mudança de patamar. O data center precisa avaliar se o território “se comporta bem” em estresse. Isso não é julgamento sobre atores. É uma leitura objetiva do sistema local e de como ele opera sob contingência.
O que compõe resiliência territorial para data centers
A seguir, um conjunto de dimensões recomendadas para incorporar ao modelo de seleção, mantendo tom estritamente técnico e descritivo.
1. Qualidade de continuidade do serviço de distribuição elétrica
O objetivo é quantificar e comparar o risco de interrupção e o comportamento de recomposição. Indicadores típicos incluem DEC (Duração Equivalente de Interrupção por Unidade Consumidora) e FEC (Frequência Equivalente de Interrupção por Unidade Consumidora), complementados por métricas internacionais como SAIDI (System Average Interruption Duration Index) e SAIFI (System Average Interruption Frequency Index), quando disponíveis ou inferíveis.
Como usar esses indicadores sem ruído institucional
- Tratar como insumo de engenharia, não como narrativa.
- Comparar séries históricas e tendências, e não apenas um episódio.
- Cruzar com perfil do território (densidade arbórea, rede aérea/subterrânea, topologia, corredores críticos).
- Transformar em decisões de arquitetura: redundância de alimentação, dual feed, autonomia de UPS (Uninterruptible Power Supply), capacidade de geração, estratégia de combustível, contratos de manutenção e testes.
2. Capacidade de resposta e recomposição em contingência
Para data centers, o tempo de recomposição é tão importante quanto a probabilidade de interrupção. A diligência deve mapear, de forma objetiva, como o ecossistema local opera em crise: mobilização, logística, acesso ao local, coordenação com trânsito, comunicação, segurança e restabelecimento de serviços essenciais.
Perguntas de diligência típicas
- Existe plano de contingência público e atualizado?
- Há rotinas de simulação (exercícios de mesa) e aprendizados incorporados?
- Os canais de comunicação com a população e com empresas críticas são estruturados?
- Há histórico de incidentes com recomposição rápida e previsível, e registros documentados?
3. Gestão urbana que afeta diretamente infraestrutura
Muitos riscos de data center são “urbanos” antes de serem “elétricos”. Exemplos clássicos: quedas de árvores, alagamentos, obstrução de vias e impactos em cabos e postes. A diligência deve considerar:
- Arborização e interferências com rede: Mapear corredores críticos, rotinas de poda preventiva, cadastros de árvores de risco e integração de informações entre atores. O ponto aqui é reduzir variabilidade e incerteza, especialmente em eventos extremos.
- Drenagem e alagamentos: Checar histórico de alagamento, capacidade de drenagem, obras e manutenção, e a exposição de rotas de acesso ao campus. O que derruba um data center muitas vezes não é a sala elétrica; é a impossibilidade de acesso, reabastecimento e operação logística.
- Ilhas de calor e microclima: Avaliar impactos no desenho de refrigeração, resiliência de HVAC (Heating, Ventilation and Air Conditioning) e riscos associados a ondas de calor.
4. Capacidade institucional e coordenação interorganizacional
Em crises, a performance do sistema depende de coordenação. Para data centers, isso se traduz em: previsibilidade de licenciamento, agilidade de respostas, clareza de papéis e capacidade de integração. Uma prática recomendada é exigir evidências de governança, não promessas.
Ferramenta prática
Construir uma matriz RACI (Responsible, Accountable, Consulted, Informed) para implantação e operação em contingência, deixando claro quem é responsável, quem aprova, quem é consultado e quem precisa ser informado, em temas como:
- acesso e perímetro
- interdições e rotas alternativas
- resposta a incidentes e segurança
- comunicação com a comunidade e com clientes críticos
5. Previsibilidade regulatória, institucional e de expansão
Data centers são projetos de ciclo longo. A decisão de localização deve avaliar a previsibilidade das regras do jogo: licenças, obras de infraestrutura, expansão do sistema elétrico e telecom, e coerência de políticas públicas locais com infraestrutura crítica e economia digital.
Aqui, a melhor prática corporativa é tratar a previsibilidade como risco mensurável:
- lead time histórico de licenças semelhantes
- estabilidade de requisitos e padrões
- capacidade de emitir autorizações e fiscalizações com cadência previsível
- qualidade de documentação e transparência de processos
Como transformar isso em modelo decisório: a matriz multicritério
Uma abordagem eficaz para o comitê é criar uma matriz multicritério com pesos e pontuações, evitando decisões baseadas em impressões. Recomenda-se usar uma escala simples (por exemplo, 1 a 5) e pesos por criticidade, com evidência mínima exigida por critério. Exemplo de estrutura:
| Bloco | Foco | Peso | Critérios de avaliação |
|---|---|---|---|
| A | Infraestrutura essencial | Alto | Energia: capacidade, expansão, redundância, qualidade e continuidade. Telecom: diversidade de rotas, múltiplos carriers, latência, redundância. Água e refrigeração: disponibilidade e estratégia (incluindo alternativas de baixo consumo). |
| B | Risco físico e climático | Alto | Ventos extremos, tempestades, descargas atmosféricas, alagamentos, incêndios e ondas de calor. Acesso e logística sob contingência. |
| C | Resiliência territorial e governança | Alto | Histórico de continuidade e recomposição. Capacidade de coordenação e planos de crise. Gestão urbana relevante (arborização, drenagem, obras e manutenção). |
| D | Implantação e operação | Médio | Mão de obra técnica, fornecedores, suporte de O&M (Operations and Maintenance), segurança do entorno. |
| E | Compliance e reputação | Médio | Requisitos ambientais, auditorias, segurança cibernética e rastreabilidade de decisões. |
O ganho dessa matriz é padronizar o debate. Se o território é excelente em energia e telecom, mas tem baixa previsibilidade de recomposição ou alto risco urbano, isso aparece numericamente. E, quando aparece, a empresa pode reagir com duas alavancas: escolher outro local ou compensar com arquitetura (o que tem custo). O essencial é que a decisão se torne consciente e auditável.
Diligência de campo: o que fazer além do “Google e planilha”
Para evitar que a análise vire um exercício teórico, recomenda-se uma diligência em três etapas, com governança clara e documentação.
Etapa 1: triagem e shortlist
Selecionar regiões candidatas com base em pré-requisitos e dados públicos: energia e telecom, clima, logística, zoneamento e disponibilidade de áreas.
Etapa 2: diligência estruturada com evidências
- Coleta de indicadores de continuidade e recomposição, com séries históricas quando possível.
- Entrevistas técnicas com atores relevantes, em formato padronizado.
- Visitas de campo para validação de rotas, acessos, drenagem, entorno e interferências.
- Verificação de planos de contingência e rotinas de coordenação.
Etapa 3: simulação e validação de resiliência
Conduzir um tabletop exercise (exercício de mesa) com cenários plausíveis: tempestade severa, alagamento em rotas de acesso, queda de árvore e bloqueio parcial, falha regional de telecom. O objetivo é testar a lógica de resposta e a capacidade de coordenação, não avaliar pessoas.
Como isso reduz custo e aumenta performance do data center
Um ponto de gestão: quando o território é incerto, a tendência é compensar com CAPEX (Capital Expenditure) elevado em redundância e autonomia. Isso funciona, mas pode ser caro e subótimo. Um território mais previsível permite:
- arquitetura mais eficiente, com redundância calibrada
- menor risco de indisponibilidade prolongada por fatores externos
- melhor cumprimento de SLA (Service Level Agreement) com menor custo marginal
- maior confiança para expansão do campus, reduzindo risco de “estrangulamento” por licenças ou infraestrutura
Do ponto de vista estratégico, isso também melhora a narrativa para clientes corporativos: o data center não vende apenas megawatts e racks. Vende continuidade como produto.
Recomendação executiva: checklist mínimo para decisão de localização
Para fechar, um checklist mínimo, adequado para uso em comitê:
- Energia: Indicadores históricos de continuidade (DEC/FEC) e leitura de recomposição. Plano de expansão e redundância de alimentação. Qualidade de energia e incidência de distúrbios relevantes.
- Telecom: Dois ou mais caminhos físicos independentes, validados em campo. Múltiplos carriers com rotas não correlacionadas.
- Risco físico e climático: Histórico e projeções de eventos extremos. Drenagem e acessos sob contingência.
- Resiliência territorial: Evidências de planos de crise e coordenação. Capacidade de resposta e comunicação. Gestão urbana relevante (vegetação, obras, manutenção de vias).
- Governança e previsibilidade: Licenciamento com trilha clara e prazos realistas. Matriz RACI para implantação e operação em contingência. Documentação e rastreabilidade para auditoria e clientes.
Conclusão
A seleção do local de um data center precisa evoluir do “tripé clássico” para um modelo de decisão orientado a resiliência territorial. O caso reportado pelo Estadão em dezembro de 2025, descrito aqui de forma neutra, é um lembrete de que eventos extremos e impactos em serviços essenciais podem acionar processos regulatórios e institucionais de grande complexidade. Para um data center, isso se traduz em risco operacional, reputacional e financeiro.
A boa prática corporativa é simples e sofisticada ao mesmo tempo: incluir critérios adicionais, tratá-los com evidências, transformá-los em matriz comparável e governar a decisão com disciplina. É assim que se protege a continuidade digital, sem depender de suposições, e com uma visão de futuro que valoriza o básico bem feito: engenharia, redundância calibrada, processos claros e governança madura do território.
Como podemos ajudar
Podemos ajudar como uma camada independente de inteligência e governança para suportar a decisão de localização de data centers, reduzindo risco e aumentando previsibilidade para o comitê executivo e para investidores, sem personalizar discussões ou atribuir responsabilidades a atores locais.
Entregáveis recomendados
- Framework de decisão e matriz multicritério: Estruturação do modelo Bloco A–E com pesos, critérios, evidências mínimas exigidas e método de pontuação comparável entre cidades/regiões, gerando uma shortlist auditável e defensável.
- Diligência de resiliência territorial: Compilação e normalização de indicadores públicos e operacionais (continuidade, recomposição, risco físico/climático, logística em contingência), com leitura técnica orientada a impacto em SLA (Service Level Agreement), TCO (Total Cost of Ownership) e expansion readiness.
- Relatório executivo para Investment Committee: Documento “board-ready” com: racional da decisão, trade-offs, riscos de cauda (tail risks), cenários e recomendações de mitigação (arquitetura, redundância, processos e governança), em linguagem adequada para diretoria e stakeholders.
- Cenários e stress test operacional: Condução de tabletop exercise (exercício de mesa) com cenários realistas (tempestade, alagamento, falha regional de telecom, restrição de acesso), produzindo plano de ação, matriz RACI (Responsible, Accountable, Consulted, Informed) e recomendações de contingência.
- Estratégia de relacionamento institucional e comunicação neutra: Desenho de roteiro de engajamento técnico com atores locais (distribuição, telecom, município e órgãos de resposta), com Q&A e pacotes de mensagens neutras e descritivas para reduzir ruído e acelerar alinhamentos durante implantação e operação.
- Roadmap de mitigação e arquitetura: Tradução dos achados em decisões de engenharia (redundância, dual feed, autonomia de UPS (Uninterruptible Power Supply), geração, combustível, rotas alternativas, contratos de O&M (Operations and Maintenance)), com priorização por impacto e custo.
Resultado esperado
Uma decisão de localização mais robusta, com rastreabilidade e governança, que reduz risco operacional e reputacional, melhora a previsibilidade de implantação e fortalece a narrativa de resiliência do data center para clientes corporativos e investidores.