
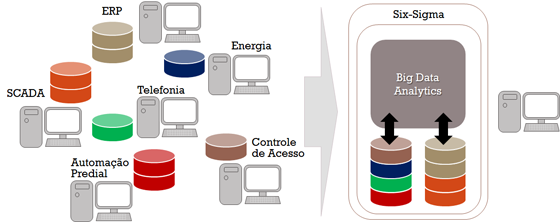
O grande desafio da automação industrial, predial e de concessionárias de serviços públicos (energia, água, petróleo, gás entre outros) é reduzir o número de falhas para aumentar a eficiência, objetivando menores custos de operação. O cenário tecnológico é complexo, não apenas pelas características de medições e controles, mas pela quantidade de padrões e soluções proprietárias dos fornecedores. Os sistemas SCADA (Supervisory Control And Data Acquisition) monitoram e supervisionam as variáveis e os dispositivos de sistemas de controle conectados através de controladores (drivers) específicos. O Six-Sigma, um conjunto de práticas para melhoria contínua de processos e eliminação de defeitos, tem ajudado a aperfeiçoar os processos industriais e de supervisão e controle, com ganhos significativos de desempenho. Agora entra no cenário o Big Data, uma tecnologia que coleta, armazena e manipula grandes volumes de dados e velocidade, permitindo analises mais precisas, rápidas e preditivas.
Os sistemas SCADA monitoram as variáveis do processo produtivo (pressão, temperatura, vazão, demanda e consumo de energia, etc.) permitindo definir níveis ótimos de trabalho. A partir da definição e monitoração dos parâmetros de operação, qualquer alteração é sinalizada para evitar um problema no processo produtivo. O sistema SCADA é essencial para realizar a leitura dos instrumentos, gerar gráficos de tendências e gráficos históricos das variáveis do processo. Permitindo uma leitura rápida dos instrumentos de campo, as intervenções necessárias são feitas rapidamente, reduzindo as paradas de máquina e, consequentemente, aumentando a disponibilidade dos serviços e perdas de produção.
Com os dados produzidos pelos sistemas SCADA é possível aplicar a metodologia DMAIC e DMADV do Six-Sigma, inspiradas no ciclo PDCA (Plan-Do-Check-Act). O DMAIC (Define-Measure-Analyse-Improve-Control) é utilizado em projetos focados em melhorar processos produtivos já existentes. O DMADV (Define-Measure-Analyse-Design-Verify) é focado em novos projetos de desenhos de produtos e processos. O DMADV também é conhecido com DFSS – Design for Six Sigma.
Um dos desafios dos projetos de melhoria contínua e inovação é utilizar de forma integrada os dados de vários sistemas SCADA de diferentes processos produtivos, permitindo que haja análises de relacionamento e comportamento de diferentes parâmetros e, análises preditivas. Essa integração exige além da simples coleta e gravação de dados, mas a exploração e transformação de alguns dados para criar uma base de dados consistente. Por exemplo, um sistema SCADA grava todos os dados que calcula um determinado parâmetro. Outros, gravam apenas o resultado do parâmetro já calculado. Desta forma, é necessário a partir dos dados já calculados definir os dados primitivos que geraram aquele resultado.
Com a popularização e maturidade dos sistemas Big Data é possível coletar, transformar, armazenar, integrar e analisar dados de diferentes sistemas SCADA com rapidez e custos com excelentes relações custo/benefícios.
Sistemas Big Data se caracterizam por apresentarem grande velocidade de processamento, terem a capacidade para manipular grandes volumes e variedade de dados, conhecidos como “3Vs” (Volume, Velocidade, Variedade). Permite analisar e gerenciar aspectos como variabilidade, veracidade e complexidade dos dados. O Big Data supera os sistemas de Data Warehouse, pois possibilitam analises de grandes volumes de dados, voláteis ou não, com maior velocidade. Diferem dos sistemas de BI (Business Intelligence), pois permitem além das análises estatísticas descritivas do BI usar modelos matemáticos de inferência estatística, cujo o objetivo é fazer afirmações a partir de uma amostra representativa, métodos de identificação que trabalham com dados de entradas e saídas e sistemas não lineares. Essas características elevam as análises de dados a um outro patamar, melhorando os resultados dos projetos e a competitividade das empresas.
A integração dos sistemas SCADA usando Big Data aumenta a proteção lógica dos dados de ataques cibernéticos, pois é possível identificar pequenas variações de comportamento dos parâmetros dos sistemas e tomar ações de defesa antes que ocorram prejuízos maiores.
As tecnologias já estão disponíveis e maduras, inclusive algumas delas na modalidade de Open Source. Um grande desafio é contar com profissionais habilitados para operar essas novas tecnologias e modelos de análise mais sofisticados. Isso requer investimento por parte das empresas e paciência durante a curva de aprendizagem. Entretanto, os resultados no futuro compensarão o esforço.